What Are Brocks Two Arguments Again Pas
Notebook workflows
The %run command allows you lot to include another notebook within a notebook. Yous can use %run to modularize your code, for case past putting supporting functions in a separate notebook. Y'all tin too employ information technology to concatenate notebooks that implement the steps in an analysis. When you use %run , the called notebook is immediately executed and the functions and variables defined in information technology become available in the calling notebook.
Notebook workflows are a complement to %run because they let you lot pass parameters to and render values from a notebook. This allows you to build complex workflows and pipelines with dependencies. For example, you tin get a list of files in a directory and pass the names to some other notebook, which is not possible with %run . You lot can also create if-so-else workflows based on return values or call other notebooks using relative paths.
To implement notebook workflows, use the dbutils.notebook.* methods. Unlike %run , the dbutils.notebook.run() method starts a new job to run the notebook.
These methods, similar all of the dbutils APIs, are bachelor only in Python and Scala. Nevertheless, you can use dbutils.notebook.run() to invoke an R notebook.
Note
Just notebook workflow jobs taking thirty days or less to complete are supported.
API
The methods bachelor in the dbutils.notebook API to build notebook workflows are: run and exit . Both parameters and return values must be strings.
run(path: String, timeout_seconds: int, arguments: Map): String
Run a notebook and render its exit value. The method starts an ephemeral job that runs immediately.
The timeout_seconds parameter controls the timeout of the run (0 ways no timeout): the phone call to run throws an exception if it doesn't finish within the specified fourth dimension. If Databricks is down for more than than ten minutes, the notebook run fails regardless of timeout_seconds .
The arguments parameter sets widget values of the target notebook. Specifically, if the notebook you are running has a widget named A , and you pass a key-value pair ("A": "B") as part of the arguments parameter to the run() call, so retrieving the value of widget A will return "B" . You lot tin can find the instructions for creating and working with widgets in the Widgets article.
Warning
The arguments parameter accepts only Latin characters (ASCII character ready). Using non-ASCII characters will render an mistake. Examples of invalid, not-ASCII characters are Chinese, Japanese kanjis, and emojis.
run Usage
dbutils . notebook . run ( "notebook-name" , 60 , { "argument" : "data" , "argument2" : "data2" , ... }) dbutils . notebook . run ( "notebook-proper name" , 60 , Map ( "statement" -> "information" , "argument2" -> "data2" , ...)) run Instance
Suppose you accept a notebook named workflows with a widget named foo that prints the widget'southward value:
dbutils . widgets . text ( "foo" , "fooDefault" , "fooEmptyLabel" ) print dbutils . widgets . go ( "foo" ) Running dbutils.notebook.run("workflows", 60, {"foo": "bar"}) produces the following result:
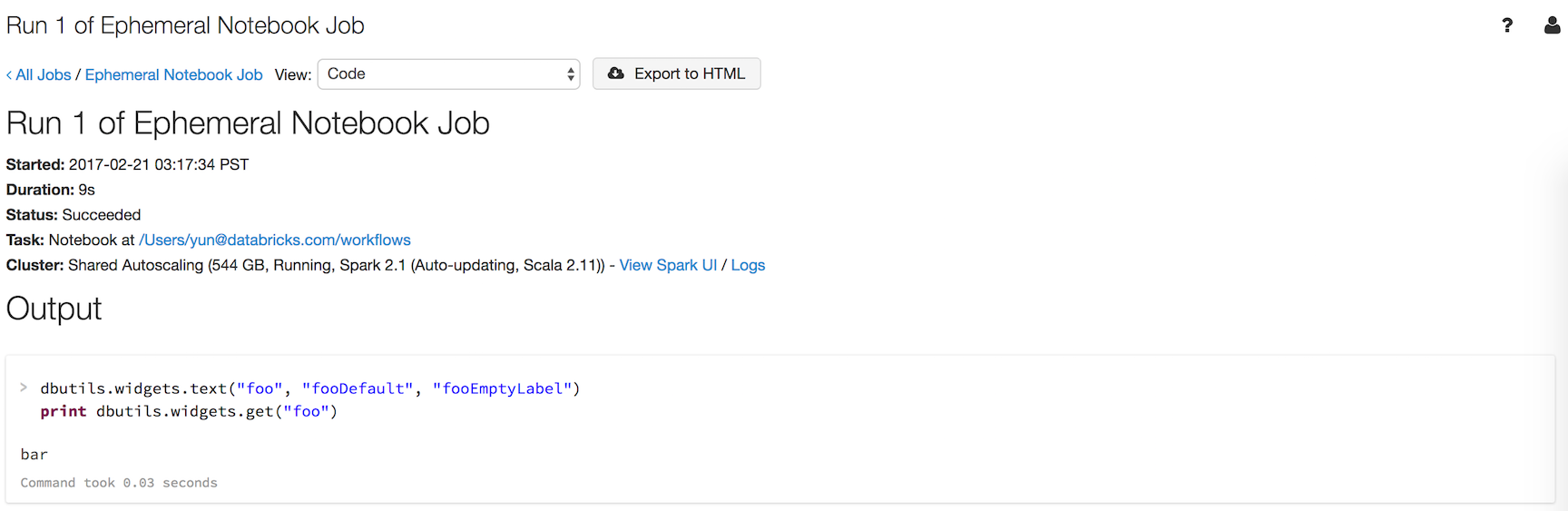
The widget had the value you passed in through the workflow, "bar" , rather than the default.
exit(value: String): void Exit a notebook with a value. If you lot phone call a notebook using the run method, this is the value returned.
dbutils . notebook . exit ( "returnValue" ) Calling dbutils.notebook.exit in a chore causes the notebook to complete successfully. If you want to cause the task to neglect, throw an exception.
Instance
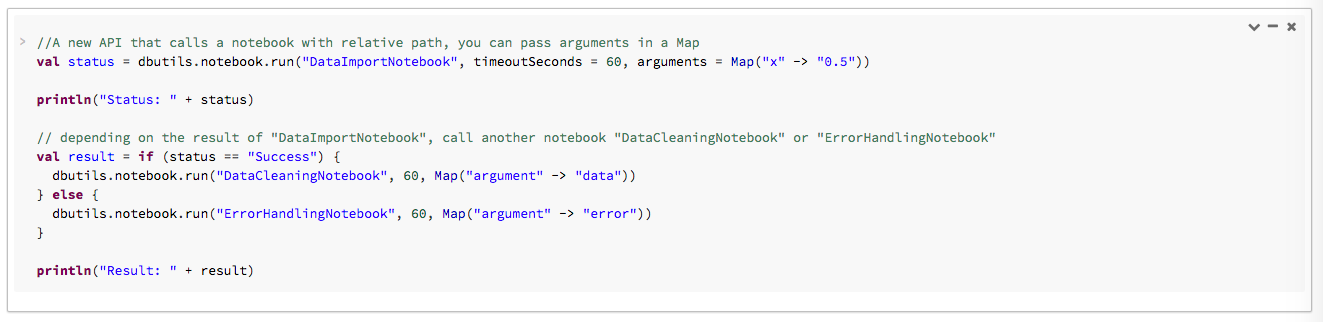
In the following example, you pass arguments to DataImportNotebook and run unlike notebooks ( DataCleaningNotebook or ErrorHandlingNotebook ) based on the result from DataImportNotebook .
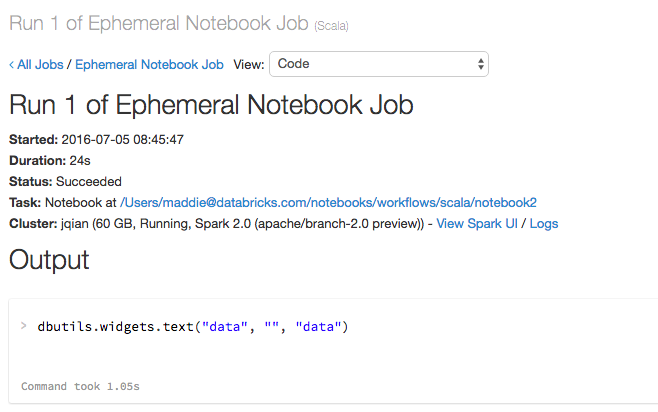
When the notebook workflow runs, you see a link to the running notebook:

Click the notebook link Notebook job #xxxx to view the details of the run:
Pass structured information
This department illustrates how to pass structured data betwixt notebooks.
# Example 1 - returning data through temporary views. # You lot tin can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can # return a name referencing data stored in a temporary view. ## In callee notebook spark . range ( 5 ) . toDF ( "value" ) . createOrReplaceGlobalTempView ( "my_data" ) dbutils . notebook . go out ( "my_data" ) ## In caller notebook returned_table = dbutils . notebook . run ( "LOCATION_OF_CALLEE_NOTEBOOK" , sixty ) global_temp_db = spark . conf . get ( "spark.sql.globalTempDatabase" ) display ( tabular array ( global_temp_db + "." + returned_table )) # Example 2 - returning data through DBFS. # For larger datasets, y'all tin can write the results to DBFS and so return the DBFS path of the stored information. ## In callee notebook dbutils . fs . rm ( "/tmp/results/my_data" , recurse = True ) spark . range ( 5 ) . toDF ( "value" ) . write . parquet ( "dbfs:/tmp/results/my_data" ) dbutils . notebook . leave ( "dbfs:/tmp/results/my_data" ) ## In caller notebook returned_table = dbutils . notebook . run ( "LOCATION_OF_CALLEE_NOTEBOOK" , 60 ) display ( spark . read . parquet ( returned_table )) # Example 3 - returning JSON data. # To return multiple values, you can use standard JSON libraries to serialize and deserialize results. ## In callee notebook import json dbutils . notebook . exit ( json . dumps ({ "status" : "OK" , "table" : "my_data" })) ## In caller notebook effect = dbutils . notebook . run ( "LOCATION_OF_CALLEE_NOTEBOOK" , 60 ) print ( json . loads ( result )) // Example 1 - returning information through temporary views. // You can only return one string using dbutils.notebook.exit(), simply since called notebooks reside in the same JVM, you can // return a proper name referencing data stored in a temporary view. /** In callee notebook */ sc . parallelize ( 1 to 5 ). toDF (). createOrReplaceGlobalTempView ( "my_data" ) dbutils . notebook . exit ( "my_data" ) /** In caller notebook */ val returned_table = dbutils . notebook . run ( "LOCATION_OF_CALLEE_NOTEBOOK" , sixty ) val global_temp_db = spark . conf . go ( "spark.sql.globalTempDatabase" ) display ( table ( global_temp_db + "." + returned_table )) // Example 2 - returning data through DBFS. // For larger datasets, you can write the results to DBFS and then render the DBFS path of the stored data. /** In callee notebook */ dbutils . fs . rm ( "/tmp/results/my_data" , recurse = truthful ) sc . parallelize ( 1 to 5 ). toDF (). write . parquet ( "dbfs:/tmp/results/my_data" ) dbutils . notebook . exit ( "dbfs:/tmp/results/my_data" ) /** In caller notebook */ val returned_table = dbutils . notebook . run ( "LOCATION_OF_CALLEE_NOTEBOOK" , 60 ) display ( sqlContext . read . parquet ( returned_table )) // Example 3 - returning JSON data. // To return multiple values, y'all can use standard JSON libraries to serialize and deserialize results. /** In callee notebook */ // Import jackson json libraries import com . fasterxml . jackson . module . scala . DefaultScalaModule import com . fasterxml . jackson . module . scala . experimental . ScalaObjectMapper import com . fasterxml . jackson . databind . ObjectMapper // Create a json serializer val jsonMapper = new ObjectMapper with ScalaObjectMapper jsonMapper . registerModule ( DefaultScalaModule ) // Exit with json dbutils . notebook . get out ( jsonMapper . writeValueAsString ( Map ( "status" -> "OK" , "table" -> "my_data" ))) /** In caller notebook */ val event = dbutils . notebook . run ( "LOCATION_OF_CALLEE_NOTEBOOK" , 60 ) println ( jsonMapper . readValue [ Map [ Cord , String ]]( outcome )) Handle errors
This section illustrates how to handle errors in notebook workflows.
# Errors in workflows thrown a WorkflowException. def run_with_retry ( notebook , timeout , args = {}, max_retries = 3 ): num_retries = 0 while Truthful : try : return dbutils . notebook . run ( notebook , timeout , args ) except Exception as due east : if num_retries > max_retries : raise e else : print ( "Retrying error" , e ) num_retries += 1 run_with_retry ( "LOCATION_OF_CALLEE_NOTEBOOK" , 60 , max_retries = 5 ) // Errors in workflows thrown a WorkflowException. import com . databricks . WorkflowException // Since dbutils.notebook.run() is just a function call, you tin can retry failures using standard Scala effort-grab // control flow. Here we evidence an example of retrying a notebook a number of times. def runRetry ( notebook : String , timeout : Int , args : Map [ String , Cord ] = Map . empty , maxTries : Int = 3 ): String = { var numTries = 0 while ( true ) { try { render dbutils . notebook . run ( notebook , timeout , args ) } catch { example e : WorkflowException if numTries < maxTries => println ( "Error, retrying: " + e ) } numTries += one } "" // non reached } runRetry ( "LOCATION_OF_CALLEE_NOTEBOOK" , timeout = 60 , maxTries = 5 ) Run multiple notebooks concurrently
You tin run multiple notebooks at the same time by using standard Scala and Python constructs such as Threads (Scala, Python) and Futures (Scala, Python). The advanced notebook workflow notebooks demonstrate how to utilise these constructs. The notebooks are in Scala but y'all could hands write the equivalent in Python. To run the example:
-
Download the notebook archive.
-
Import the archive into a workspace.
-
Run the Concurrent Notebooks notebook.
Source: https://docs.databricks.com/notebooks/notebook-workflows.html
0 Response to "What Are Brocks Two Arguments Again Pas"
Enviar um comentário